Exploiting 3D Semantic Scene Priors for Online Traffic Light Interpretation
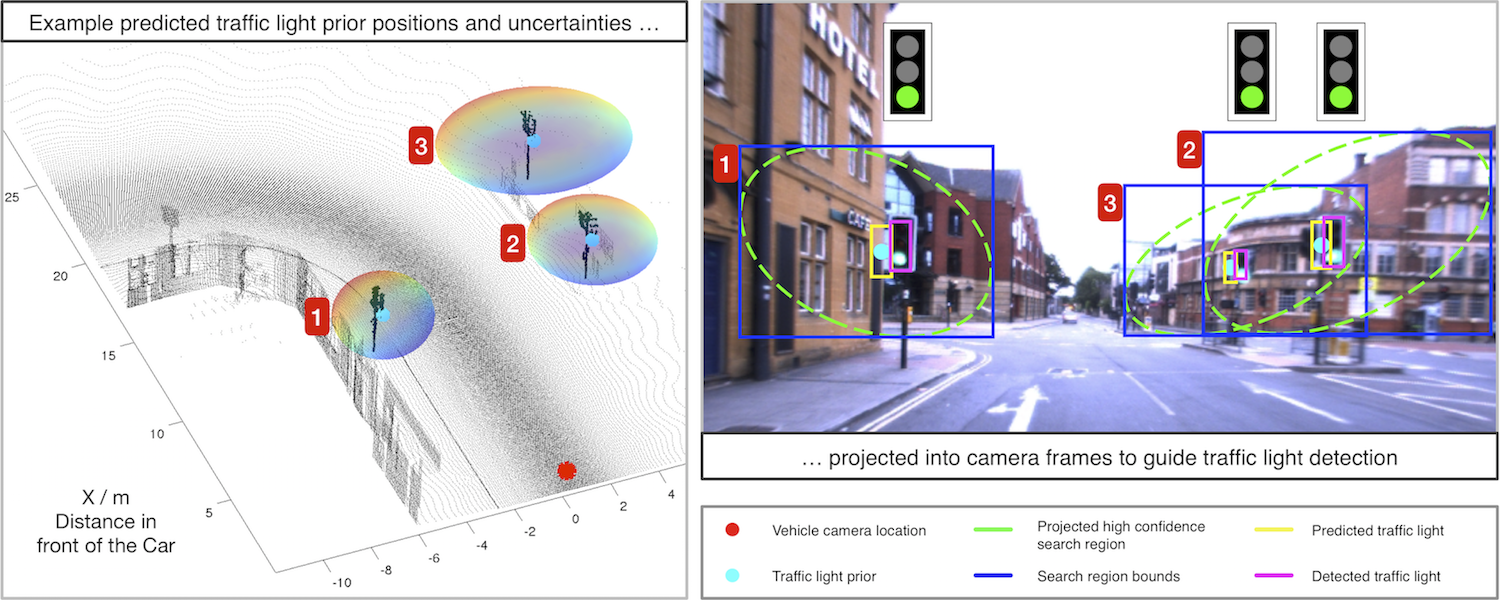
Abstract - In this paper we present a probabilistic framework for increasing online object detection performance when given a semantic 3D scene prior, which we apply to the task of traffic light detection for autonomous vehicles. Previous approaches to traffic light detection on autonomous vehicles have involved either precise knowledge of the relative 3D positions of the vehicle and the traffic light (requiring accurate and expensive mapping and localisation systems), or a classifier-based approach that searches for traffic lights in images (increasing the chance of false detections by searching all possible locations for traffic lights). We combine both approaches by explicitly incorporating both prior map and localisation uncertainty into a classifier-based object detection framework, generating a scale-space search region that only evaluates parts of the image likely to contain traffic lights, and weighting object detection scores by both the classifier score and the 3D occurrence prior distribution. We present results comparing a range of low- and high-cost localisation systems using over 30 km of data collected on an autonomous vehicle platform, demonstrating up to a 40% improvement in detection precision over no prior information and 15% improvement on unweighted detection scores. We demonstrate a 10x reduction in computation time compared to a naïve whole-image classification approach by considering only locations and scales in the image within a confidence bound of the predicted traffic light location. In addition to improvements in detection accuracy, our approach reduces computation time and enables the use of lower cost localisation sensors for reliable and cost-effective object detection.
Further Info - For more experimental details please have a look at the paper or drop me an email:
@inproceedings{
BarnesIV2015,
Address = {Seoul, South Korea},
Author = {Barnes, Dan and Maddern, Will and Posner, Ingmar},
Booktitle = {{P}roceedings of the {IEEE} {I}ntelligent {V}ehicles {S}ymposium ({IV})},
Month = {June},
Pdf = {http://www.robots.ox.ac.uk/~mobile/Papers/2015IV_barnes.pdf},
Title = {{E}xploiting {3D} {S}emantic {S}cene {P}riors for {O}nline {T}raffic {L}ight {I}nterpretation},
Year = {2015}
}